Abstract
Speech-driven 3D talking-head animation often exhibits uncontrolled phenomena, such as cross-modal misalignment, speech–expression mismatches, and abrupt transitions, which degrade emotional naturalness and erode the viewer’s sense of control. Compensatory Control Theory (CCT) in psychology posits that when individuals perceive a loss of control, they seek structure and order to restore balance. Inspired by this, we reinterpret such animation failures as “loss-of-control” events and design compensatory mechanisms to restore order. We introduce CCTalker, a diffusion-based framework that integrates three modules to enhance expressivity in generated animations collaboratively, each executing its own full CCT cycle of “loss-of-control → compensation → order restoration”. Specifically, Control–Sense Modeling (CSM) corrects frame-level deviations between intended emotion cues or continuous control strength of audio dynamics and mesh outputs. Compensatory Dynamic Enhancement (CDE) applies high-frequency enhancement or spatio-temporal smoothing to recover fine-grained details and smooth abrupt motions. Information Order Modeling (IOM) enforces causal temporal updates and cross-modal alignment constraints to realign emotional cues, temporal synchronization, and sequence-level continuity. Experiments on the 3DMEAD and BIWI datasets demonstrate that CCTalker outperforms state-of-the-art baselines, validating the effectiveness of CCT mechanisms for generating natural and expressive 3D facial animations.
Methodology
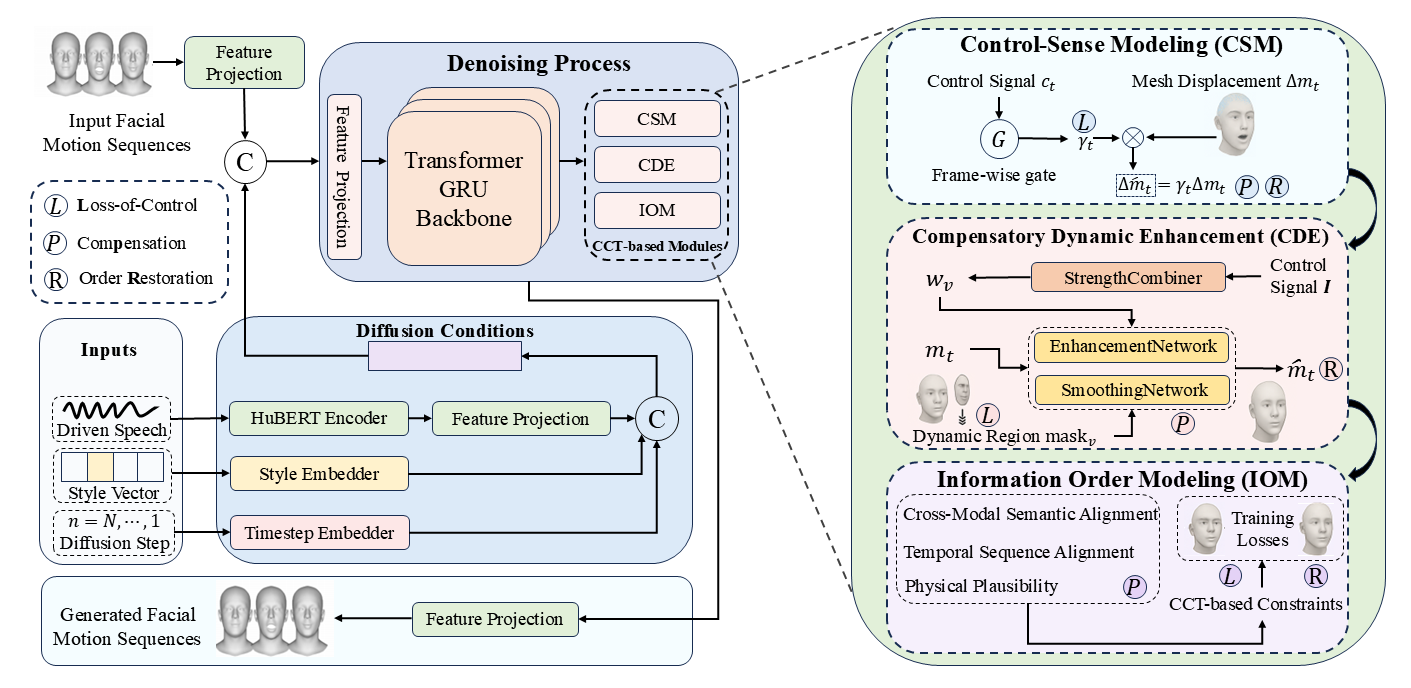
CCTalker is a diffusion-based framework embedding three parallel modules, each implementing a full CCT cycle: Control–Sense Modeling (CSM), Compensatory Dynamic Enhancement (CDE), and Information Order Modeling (IOM). These modules operate in a progressive “align → refine → integrate” flow along the generation timeline, collectively synthesizing emotionally faithful and temporally coherent 3D facial animations.
Control–Sense Modeling (CSM)
CSM monitors frame-level alignment between intended emotional cues (or continuous control strength inferred from audio dynamics) and the generated mesh. Deviations beyond a learned threshold are treated as “loss-of-control” events, triggering an adaptive gating mechanism that corrects mesh updates and enforces short-term smoothing.
Compensatory Dynamic Enhancement (CDE)
CDE identifies dynamic regions via per-vertex speed masks. Under-expressive areas receive high-frequency detail enhancement, while overly abrupt regions undergo spatio-temporal smoothing. This dual-path mechanism recovers lost geometric details and prevents jarring motions.
Information Order Modeling (IOM)
IOM enforces sequence-wide coherence by augmenting the diffusion backbone with an autoregressive temporal module. Causal alignment constraints realign cross-modal emotional cues, maintain temporal synchronization, and preserve overall sequence integrity.
BibTeX
@article{2025cctalker,
title={CCTalker: When Compensatory Control Theory Meets 3D Emotional Talking Head Animation},
author={Anonymous},
journal={arXiv preprint arXiv},
year={2025}
}